Introduction to Stateful Agents
Stateful agents are agents that can maintain memory and context across conversations.
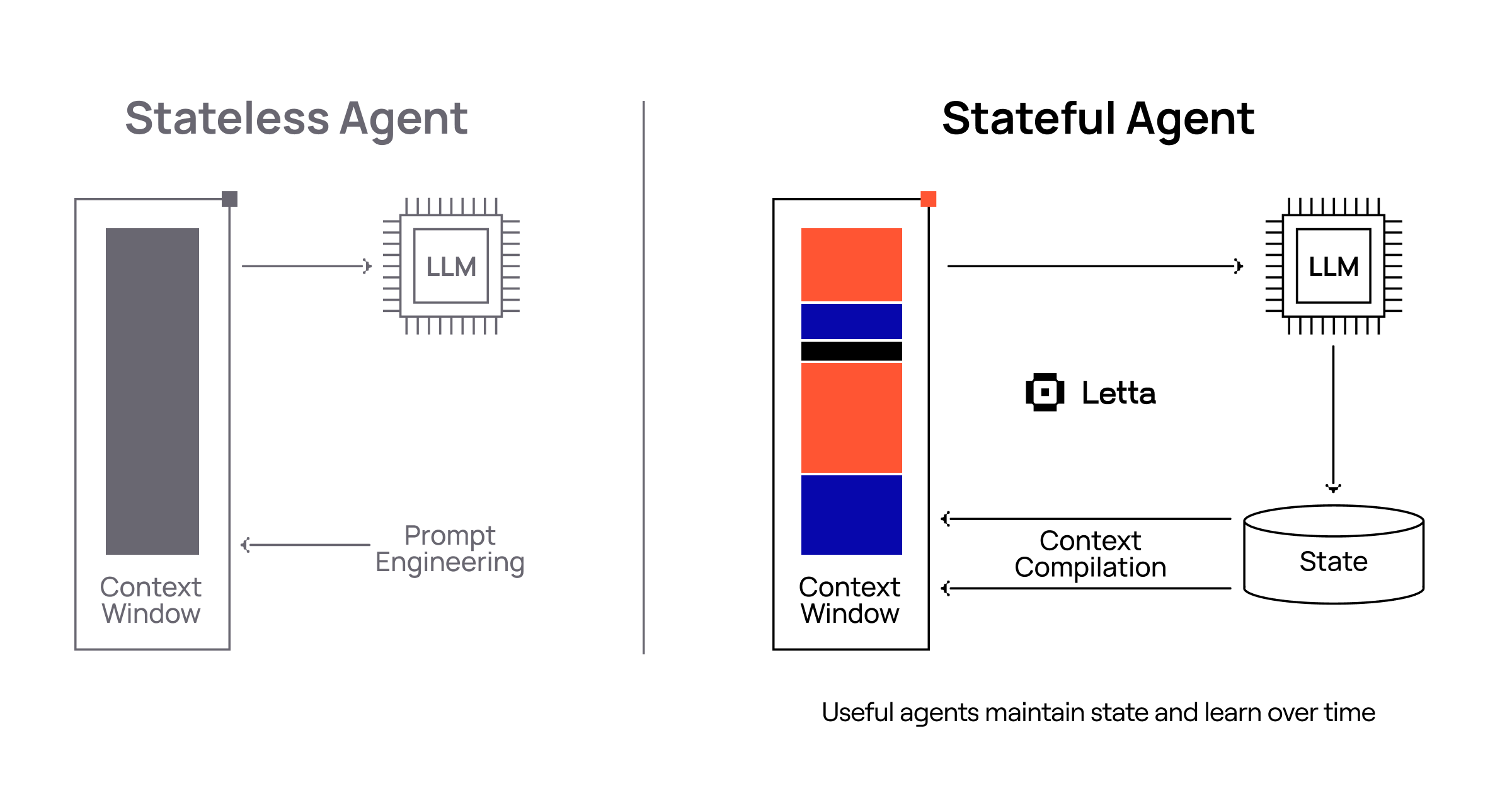

When an LLM agent interacts with the world, it accumulates state - learned behaviors, facts about its environment, and memories of past interactions. A stateful agent is one that can effectively manage this growing knowledge, maintaining consistent behavior while incorporating new experiences.
Letta provides the foundation for building stateful agents through its context management system. In Letta, all state, includes memories, user messages, reasoning, tool calls, are all persisted in a database, so they are never lost, even once evicted from the context window. Important “core” memories are injected into the context window of the LLM, and the agent can modify its own memories through tools.
Core API concepts
Section titled “Core API concepts”The Letta API is designed around a few high-level concepts:
Agents
Section titled “Agents”A stateful agent comprises of a system prompt, memory blocks, messages (in-context and out-of-context), and tools.
Tools contain JSON schema (passed to the LLM), which include a tool name, description, and keyword arguments. Server-side tools contain code (executed by the server in a sandbox), vs MCP tools and client-side tools only contain the schema (since the tool is executed externally from the agent server).
Memory
Section titled “Memory”Memory (organized into blocks) are pieces of context (strings) that are editable by agents via memory tools (and directly by the developer via the API). Memory blocks can be attached and detached from agents - memory blocks that are attached to an agent are in-context (pinned to the system prompt). Memory blocks can be attached to multiple agents at once (“shared blocks”).
Messages
Section titled “Messages”An agent’s context window contains a system prompt (which includes attached memory blocks), and messages. Messages can be generated by the user, the agent/assistant, and through tool calls. The Letta API stores all messages, so even after a compaction / eviction, an agent’s old messages are still retrievable via the API (for developers) and retrieval tools (for agents).
Runs & Steps
Section titled “Runs & Steps”A single invocation of an agent is tied to a run. A single run may contain many steps, for example, if a user asks an agent to fix a bug in a codebase, a single user input (“please fix the bug”) may trigger a sequence of many sequential steps (eg reading and writing to many files), where each step performed a single pass of LLM inference.
Conversations
Section titled “Conversations”Independent message threads with the same underlying agent, allows for easy concurrent messaging between a single agent and many different users.
Explore the complete API reference with all endpoints, parameters, and response schemas.